
Efficient AI Across Edge, Near-Edge, and Cloud
Overview
Modern applications like smart cameras, self-driving cars, and VR devices rely on powerful AI models. Running these models quickly and efficiently across phones, edge devices, and cloud servers is a tough challenge.
Our work develops two frameworks to make this possible:
- DONNA finds the best way to split and run AI models across different types of devices, from traditional CPUs and GPUs to new Compute-In-Memory (CIM) accelerators, so they use less energy while staying fast.
- HiDist takes the idea further by looking at the whole system: edge devices near the user, stronger near-edge servers, and powerful cloud machines. It decides where each part of the model should run to save energy and boost performance, instead of simply sending everything to the cloud.
Fig.1 shows this idea in action: AI models are broken into pieces and distributed across device tiers, with the system automatically choosing the best balance between speed and efficiency.
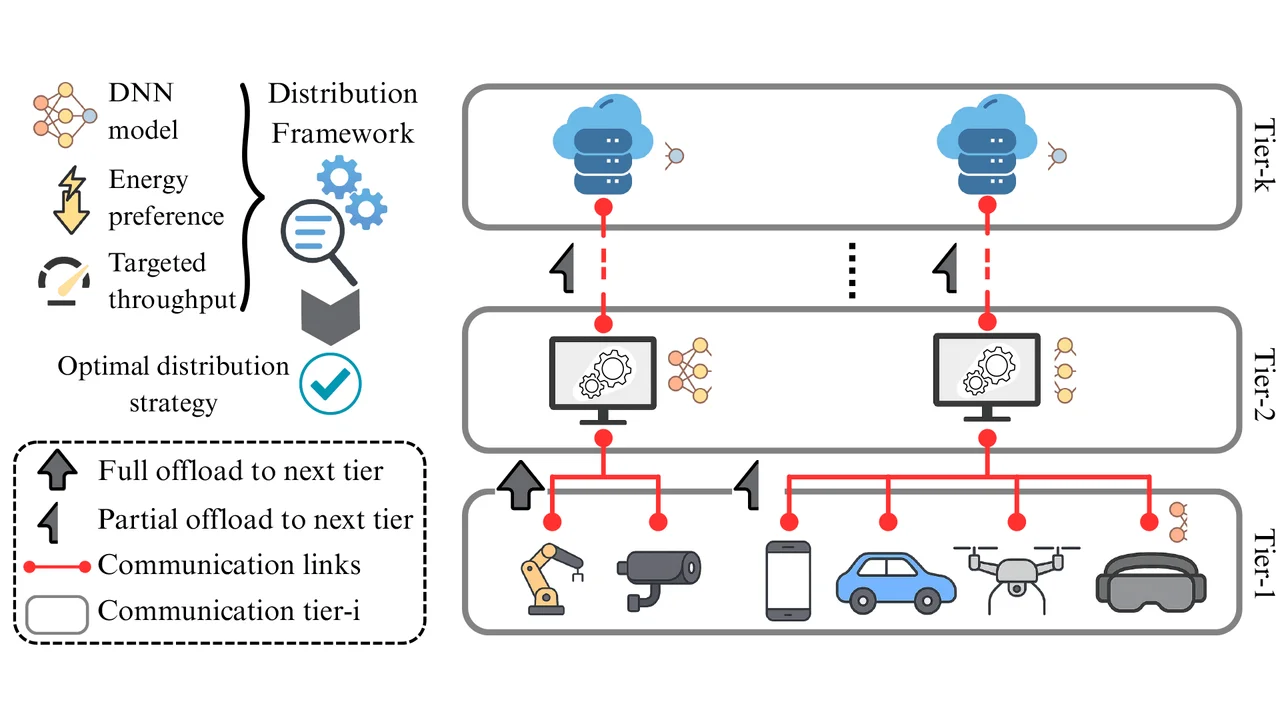
Fig. 1: A typical multi-tier edge-to-cloud network with DNN offloading guided by a search-based optimal distribution strategy.
Inside DONNA: Approach & Key Results
The Distributed Optimized Neural Network Allocation (DONNA) framework introduces a smarter way to run AI models across different devices. Instead of pushing the entire model to a single machine, DONNA carefully splits the model into pieces and assigns each part to the device best suited for it, whether that’s a CPU, GPU, or newly-emerging technology CIM.
As Fig.2 shows, DONNA uses a profiler to understand how fast and energy-efficient each device is. Then, it searches for the best distribution strategy that balances two goals at once: high throughput and low energy use. Unlike multiple earlier approaches that focused on only one of these goals, DONNA achieves both with user-controllable parameter, making it more efficient and adaptable across a variety of hardware setups.
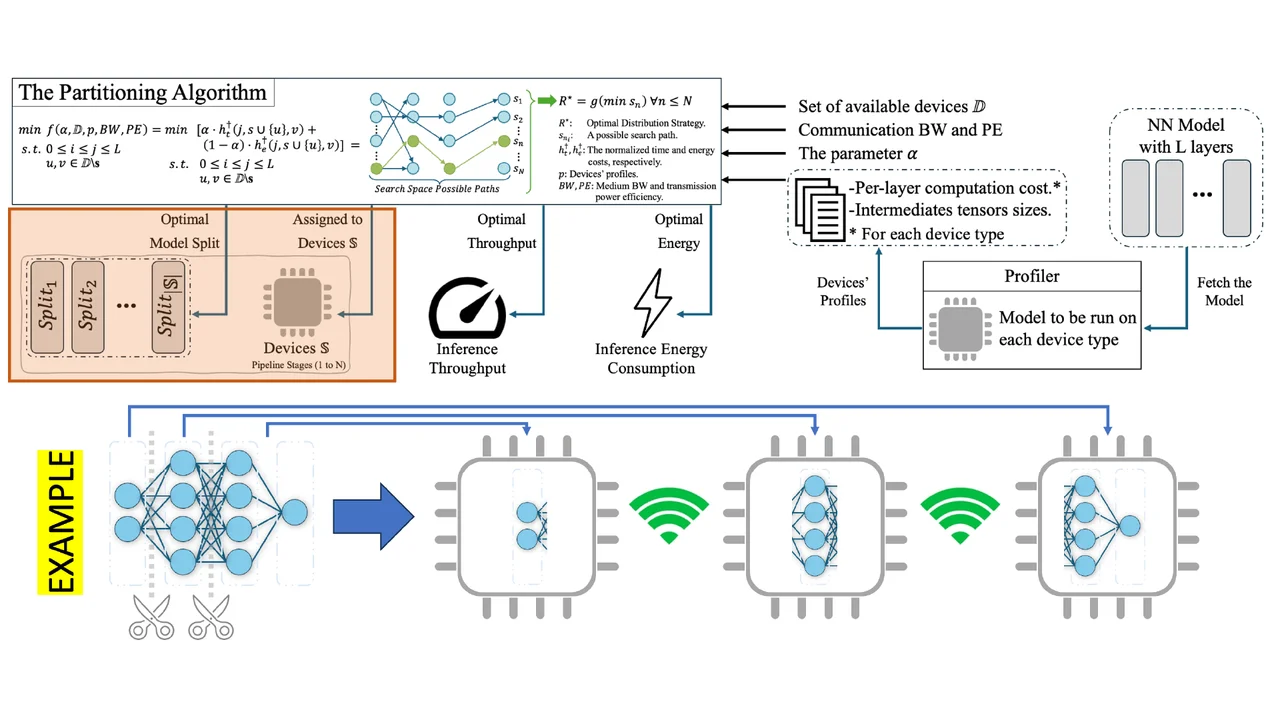
Highlighted Results
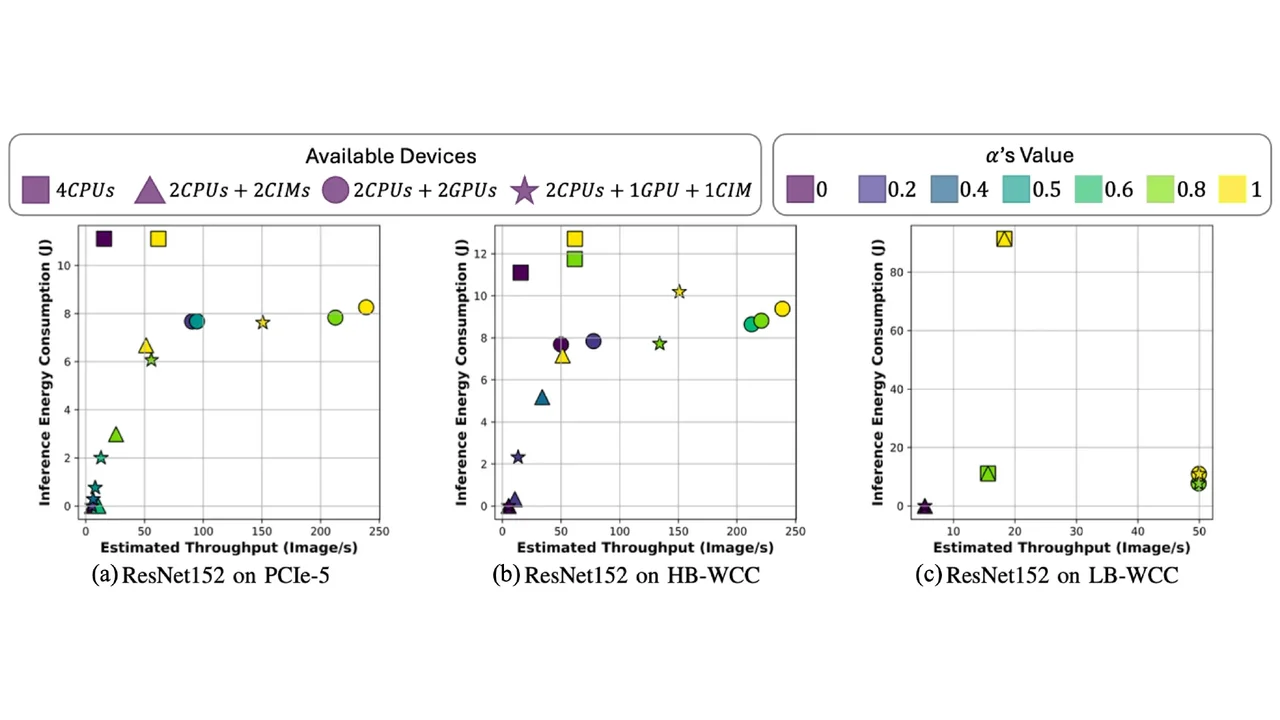
DONNA consistently finds the sweet spot between speed and energy. As shown in Fig.3, it produces smooth trade-offs, or “Pareto curves”, across devices and networks. With strong communication links and heterogenous devices (Fig. 3a), DONNA maps out a clear Pareto curve, while under weaker links (Fig. 3c), it still spreads optimization points to reflect user preferences and maintain flexibility.
HiDist: Smarter Distribution Across Tiers
While DONNA showed how to balance throughput and energy, it used a single energy-aware parameter to treat all devices the same. In reality, devices behave very differently. Some scale well with larger workloads and deliver big speedups (Fig.4a), while others are far more energy-efficient for the same task (Fig.4b).
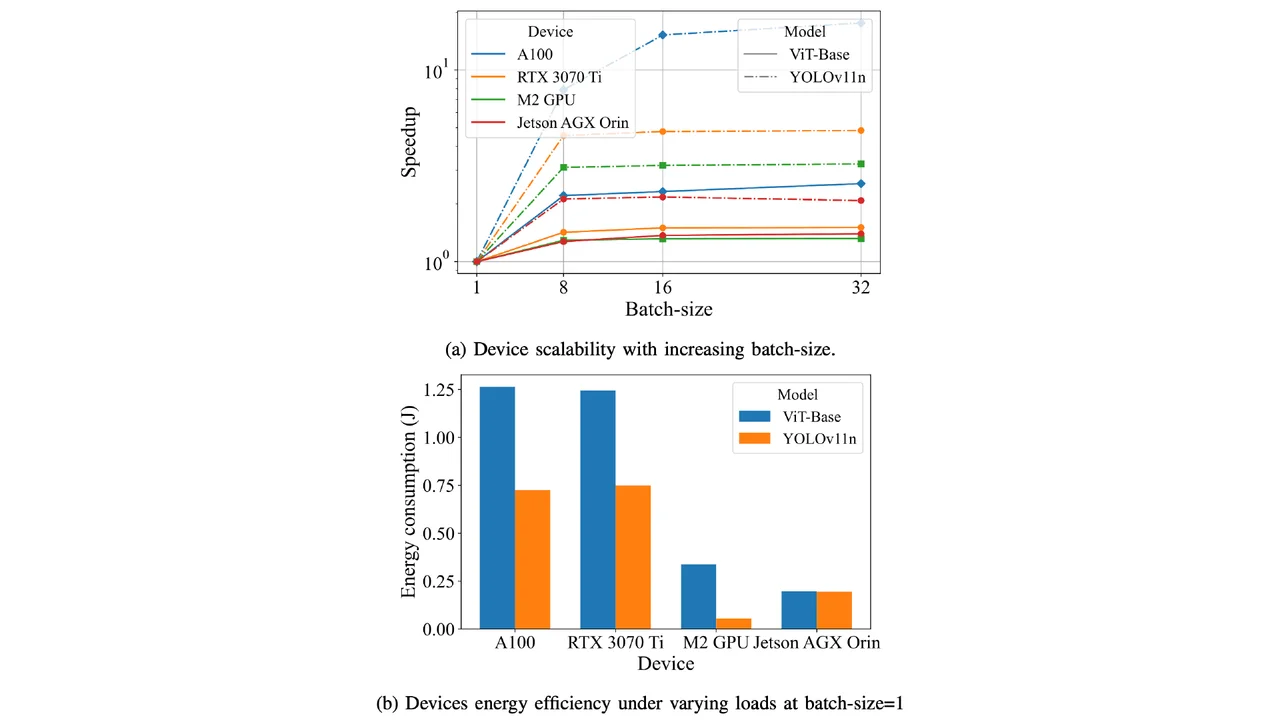
Fig. 4: HiDist leverages heterogeneity and tiered resource availability across real-world edge environments.
Highlighted Results
HiDist paper is still on-going, but even in its current form it clearly outperforms traditional “full offloading” strategies. As shown in Fig.5, instead of pushing all work to the cloud or near-edge servers, HiDist distributes it smartly across tiers. This leads to dramatic improvements, up to 7.7× faster throughput and 1.4× better energy efficiency compared to the best full offload.
What stands out is that HiDist doesn’t just chase one goal. It creates a balanced trade-off, or Pareto front, where users can benefit from both speed and efficiency, while full offloading gets stuck with poor compromises. This shows HiDist’s potential as a next-generation framework for real-world AI systems.

Watch Our Presentation
Copyright
The data and results presented in this work are protected by copyright and may only be used with proper citation. Any use of this work should reference the following papers:


